Introduction to System Design

One day I watched a YouTube video about a software engineer who worked in FAANG and mentioned how most of his days consisted of meetings, bug fixes, and hardly writing any new code.
The more senior you become, the more code you write. I was utterly wrong. Since then, I started looking at my occupation as a software engineer much differently.
What am I being hired to do?
What is system design?
System design defines the architecture, components, interfaces, and data for a system to satisfy the specified requirements. It involves identifying and defining the functional and non-functional requirements of the system, as well as the constraints and trade-offs that must be made during the development process.
The goal of system design is to create a system that is efficient, reliable, and easy to maintain while also meeting the needs of the users and stakeholders. This process typically involves a combination of both top-down and bottom-up approaches, emphasizing modularity, scalability, and reusability.
Proper system design considers the users' location, the technology being used, and the content shared throughout the network it lives in.
System design in software is essential for several reasons.
- It helps to ensure that the final product meets the needs of the users and stakeholders. By clearly defining the requirements and constraints of the system, designers can ensure that the software will be usable, efficient, and effective.
- System design allows for the creation of a scalable and modular architecture. This makes it easier to add new features or make changes to the system in the future without disrupting the existing functionality. It also enables the reuse of code and components across different projects, saving time and resources.
- System design plays a crucial role in the maintainability of the software. A well-designed system is easier to understand, test, and debug, reducing the likelihood of introducing new bugs and making fixing existing ones easier.
- System design is essential for creating efficient and high-performing software. By carefully considering the performance and scalability requirements during the design process, designers can ensure that the final product will meet the demands of the users and not cause bottlenecks or fail under heavy load.
Questions to ask before designing a software system
It’s important to note that these are just a few examples of the questions that a software engineer should consider when creating a large-scale system. The questions will depend on the system's requirements and the domain it operates in.
What are the goals and requirements of the system?
What are the expected traffic and usage patterns for the system?
How should the system handle failures and errors?
How should the system handle scalability and performance?
How should the system handle security and access control?
How should the system handle data storage and retrieval?
How should the system handle data consistency and integrity?
How should the system handle data backups and recovery?
How should the system handle monitoring and logging?
How should the system handle updates and maintenance?
How should the system handle integration with other systems and services?
How should the system handle regulatory compliance and data privacy?
How should the system handle disaster recovery and business continuity?
How should the system handle user experience and usability?
This article’s primary purpose is to help developers understand system design concepts. This is not a tutorial but more of an overview of this topic.
Now, let’s dive deeper!
Load Balancers
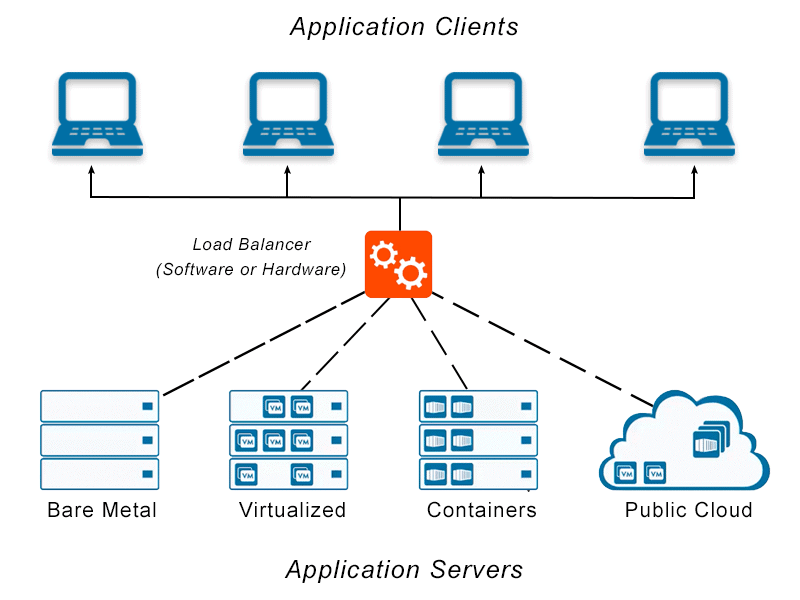
A load balancer is a device or service that distributes network or application traffic across multiple servers. A load balancer's primary purpose is to increase applications' availability and scalability by distributing the workload evenly across multiple servers. ==This ensures that no single server becomes a bottleneck and that the system can handle a high traffic volume.==
Think of trying to empty a large water tank. A load balancer helps empty the water tank by adding more holes at the bottom to increase water flow so that incoming water won't overflow out of the reservoir.
Load balancers use various algorithms to determine how to distribute the traffic, such as round-robin, where requests are sent to each server in turn, or least connections, where requests are sent to the server with the fewest active connections. Load balancers can also monitor each server's health, and if a server becomes unavailable, the load balancer will redirect traffic to the other available servers.
DNS load balancers
DNS load balancing is another popular method of distributing network traffic across multiple servers using the Domain Name System (DNS). It configures various IP addresses for a single domain name. Then it uses a DNS server to distribute incoming traffic to one of the IP addresses based on a load-balancing algorithm.
Geographic-based load balancing
Another method is geographic-based load balancing, where the DNS server routes the traffic to the closest server based on the client's location, making the request. This can improve performance and reduce latency for users as they are directed to the server closest to them.
Caching
Caching is a technique used in system design to improve the performance and scalability of a system by storing frequently accessed data in a temporary storage location, known as a cache. There are several benefits of caching in system design:
- Reduced Latency: Caching data locally can significantly reduce the time it takes to access the data, as it eliminates the need to retrieve the data from a remote location. This can result in faster response times for the end user.
- Increased Throughput: Caching can also increase the number of requests a system can handle simultaneously, as it reduces the number of requests that need to be sent to the backend server. This can help prevent the system from becoming overwhelmed during high-traffic periods.
- Reduced Load on Backend Servers: Caching can also reduce the load on backend servers by reducing the number of requests they need to handle. This can improve the overall performance and scalability of the system.
- Offline Access: Caching data locally can also enable offline access to the data, even when the backend server is unavailable. This can be particularly useful for mobile or IoT applications where connectivity is only sometimes guaranteed.
- Cost-effective: Caching can reduce the costs associated with scaling a system by reducing the load on backend servers and the need for additional hardware or network bandwidth.
==In memory caching==
In-memory caching is a type of caching that stores data in the system’s main memory (RAM) rather than on disk. This allows for faster access to the cached data, as data stored in memory can be accessed much more quickly than stored on disk.
The main advantage of in-memory caching is its high performance. Since data is stored in RAM, it can be accessed much faster than data stored on disk. This can significantly improve the response times of a system, especially for frequently accessed data.
Another advantage of in-memory caching is that it doesn’t require disk I/O operations, which can be slow and resource-intensive. This can help to reduce the load on the system and improve overall performance.
In-memory caching can be implemented using various tools and libraries, such as Memcached, Redis, and Hazelcast. These tools provide a simple interface for storing and retrieving data from memory, and they can also be used to implement distributed caching across multiple servers.
It’s worth noting that in-memory caching has limitations; mainly, the available RAM's size of the data that can be stored in memory is limited. Also, the data stored in memory is volatile, meaning it will be lost if the system is rebooted or crashes.
CDNs
Content Delivery Networks (CDNs) are a distributed network of servers that deliver content, such as web pages, images, and videos, to users based on their geographic location. CDNs can help with software caching by providing a way to cache and distribute content closer to the end-users, reducing the latency and improving the system's performance.
When a user requests content from a website or application, the request is first sent to the closest CDN server, an “edge server.” The edge server checks its cache to see if the requested content is stored locally. If the content is found in the stock, it is delivered to the user immediately. If the content is not found in the cache, the edge server retrieves it from the origin server and caches it locally for future requests.
By caching content locally on the edge servers, CDNs can reduce the load on the origin server and reduce the latency for the end user. This can be especially beneficial for websites and applications that serve many users or for users located far away from the origin server.
Additionally, CDNs can also help to improve the security and availability of the system by providing DDoS protection, SSL termination, and load balancing.
Databases
Database Schema Design
Database schema design is creating a blueprint for a database, which defines the structure of the data and the relationships between different data elements. This includes defining the tables, fields, keys, indexes, and constraints that make up the database.
A good database schema design is essential for ensuring the database is efficient, flexible, and easy to maintain. It should be based on a clear understanding of the requirements and goals of the system, and it should be designed to be scalable, secure, and reliable.
The process of database schema design typically involves several steps, including:
- Defining the entities and their relationships
- Identifying the attributes and data types for each entity
- Defining the keys and constraints for each table
- Creating indexes to improve query performance
- Normalizing the database to eliminate redundancy and improve data integrity
- Testing and documenting the schema for ease of use
It’s also important to note that design is an ongoing process, as the database needs to change and adapt over time.
==Database Indexes==
A database index is a data structure that improves the speed of data retrieval operations on a database table. It allows the database management system to quickly find and retrieve specific rows of data from the table. ==Indexes are created on one or more columns of a table, and the data in those columns is stored in a specific way (such as in a B-tree or hash table) to optimize lookup performance.==
Regarding system design, indexes can significantly improve a database-driven application's performance by reducing the time it takes to retrieve data from the table. This can be especially important in large and complex systems where there is a lot of data to be retrieved or where multiple users frequently access the data. Using indexes can also reduce the load on the database server, as the server does not need to scan the entire table to find the desired data.
It is important to note that creating indexes can also have negative impacts, such as increased disk space and update costs, so it is essential to be selective and strategic when creating indexes. It is always recommended to test the performance of your system with and without indexes, monitor the impact of indexes on your system, and adjust accordingly.
Database Sharding
Database sharding is a technique used to ==horizontally partition a large database into smaller, more manageable pieces== called shards. Each shard is a separate, independent data store that contains a ==subset of the data== from the original database. The data within ==each shard is typically organized by some key==, such as a user ID, to ensure that all the data for a specific user is in the same shard.
==Sharding can be useful in a number of different scenarios, such as when a database has grown too large to be efficiently managed by a single server, or when a high volume of read or write requests is causing performance issues. By distributing the data across multiple servers, sharding can improve the scalability and performance of a database-driven application.==
Several techniques can be used to implement sharding, such as:
-==Range-based sharding==: the data is partitioned based on a range of values, such as a user ID range,
-Hash-based sharding: the data is partitioned based on a hash function applied to a key value, such as a user ID,
-List-based sharding: the data is partitioned based on a predefined list of values, such as a country or region.
It is important to note that sharding requires a shard key, which is a field used to determine which shard a particular record belongs to. Also, it is essential to consider that sharding adds complexity to the system, so it should be considered as a last resort when other solutions, such as indexing, caching, and query optimization, are exhausted.
API Design
API (Application Programming Interface) design involves planning and creating a set of interfaces, protocols, and tools for building software and applications. The goal of API design is to provide a consistent and efficient way for different software systems to communicate and share data. This typically involves defining the methods, inputs, outputs, and other specifications for the API, as well as testing and documenting the API for ease of use.
Slave-Master Replications
In a slave-master replication setup, one database server (the master) is designated as the primary source of data, and one or more other servers (the slaves) are configured to replicate the data from the master. The master server continuously updates its data and makes these changes available to the slaves, which then copy and apply these changes to their own databases.
This type of replication is used to provide redundancy and high availability, as the slaves can be used to handle read requests and to provide failover in case the master goes down. It can also be used to scale out the read-heavy workloads.
In a master-slave replication, the master server is responsible for handling all write operations, and the slaves only replicate the data and can’t be written to. This allows the master to focus on handling writes while the slaves handle read-only queries, which can help to improve performance.
There are several different types of slave-master replication, such as statement-based, row-based or mixed replication, each with its own advantages and disadvantages, and different replication techniques, like asynchronous and semi-synchronous replication.
It’s important to note that replication can introduce data inconsistencies and it’s important to design the system in a way that these are minimized and also to have a strategy for handling replication failures.
Final Thoughts
You may feel like you are drinking from a firehouse, and that’s ok! As a software engineer, you are not expected to know everything right now. This article is just an overview of the most common topics related to system design.
I plan on making more articles related to this. Any feedback is appreciated so I can provide more value to you.
Thanks for reading!
Enjoying the content?
Learn more about me and get access to exclusive content about software engineering and best business practices.
Subscribe